How CAPTCHAs work | What does CAPTCHA mean?
CAPTCHAs and reCAPTCHAs determine if a user is actually a bot. While these tests can help stop malicious bot activity, they are far from foolproof.
Learning Objectives
After reading this article you will be able to:
- Learn what a CAPTCHA is and why they're used
- Learn the difference between CAPTCHA and Google reCAPTCHA, and the different types of reCAPTCHAs
- Understand the benefits and drawbacks of using CAPTCHAs to block malicious bots
- Explain how CAPTCHAs are related to artificial intelligence (AI) projects
Related Content
Want to keep learning?
Subscribe to theNET, Cloudflare's monthly recap of the Internet's most popular insights!
Copy article link
What is a CAPTCHA?
A CAPTCHA test is designed to determine if an online user is really a human and not a bot. CAPTCHA is an acronym that stands for "Completely Automated Public Turing test to tell Computers and Humans Apart." Users often encounter CAPTCHA and reCAPTCHA tests on the Internet. Such tests are one way of managing bot activity, although the approach has its drawbacks.
Although CAPTCHAs are designed to block automated bots, CAPTCHAs are themselves automated. They're programmed to pop up in certain places on a website, and they automatically pass or fail users.
How does a CAPTCHA work?
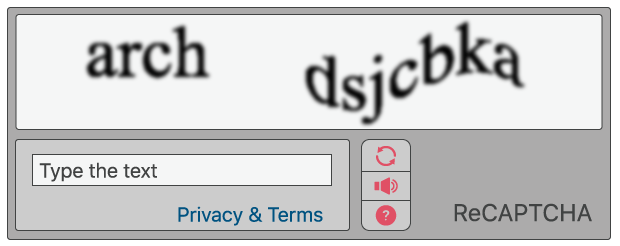
Classic CAPTCHAs, which are still in use on some web properties today, involve asking users to identify letters. The letters are distorted so that bots are not likely to be able to identify them. To pass the test, users have to interpret the distorted text, type the correct letters into a form field, and submit the form. If the letters don't match, users are prompted to try again. Such tests are common in login forms, account signup forms, online polls, and e-commerce checkout pages.

The idea is that a computer program such as a bot will be unable to interpret the distorted letters, while a human being, who is used to seeing and interpreting letters in all kinds of contexts – different fonts, different handwritings, etc. – will usually be able to identify them.
The best that many bots will be able to do is input some random letters, making it statistically unlikely that they will pass the test. Thus, bots fail the test and are blocked from interacting with the website or application, while humans are able to continue using it like normal.
Advanced bots are able to use machine learning to identify these distorted letters, so these kinds of CAPTCHA tests are being replaced with more complex tests. Google reCAPTCHA has developed a number of other tests to sort out human users from bots.
What is reCAPTCHA?
reCAPTCHA is a free service Google offers as a replacement for traditional CAPTCHAs. reCAPTCHA technology was developed by researchers at Carnegie Mellon University, then acquired by Google in 2009.
reCAPTCHA is more advanced than the typical CAPTCHA tests. Like CAPTCHA, some reCAPTCHAs require users to enter images of text that computers have trouble deciphering. Unlike regular CAPTCHAs, reCAPTCHA sources the text from real-world images: pictures of street addresses, text from printed books, text from old newspapers, and so on.
Over time, Google has expanded the functionality of reCAPTCHA tests so that they no longer have to rely on the old style of identifying blurry or distorted text. Other types of reCAPTCHA tests include:
- Image recognition
- Checkbox
- General user behavior assessment (no user interaction at all)
How does an image recognition reCAPTCHA test work?
For an image recognition reCAPTCHA test, typically users are presented with 9 or 16 square images. The images may all be from the same large image, or they may each be different. A user has to identify the images that contain certain objects, such as animals, trees, or street signs. If their response matches the responses from most other users who have submitted the same test, the answer is considered "correct" and the user passes the test.

Picking out certain objects from blurry photos is a hard problem for computers to solve. Even advanced artificial intelligence (AI) programs struggle with it – so a bot will struggle with it as well. However, a human user should be able to do this fairly easily, since humans are used to perceiving everyday objects in all kinds of contexts and situations.
How do reCAPTCHA tests with a single checkbox work?
Some reCAPTCHA tests simply prompt the user to check a box next to the statement, "I'm not a robot." However, the test is not the actual action of clicking the checkbox – it's everything leading up to the checkbox click.
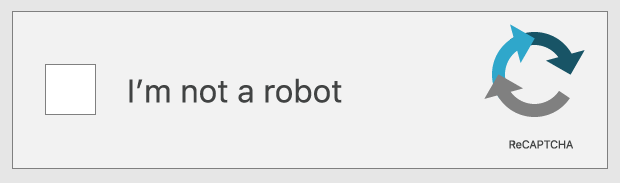
This reCAPTCHA test takes into account the movement of the user's cursor as it approaches the checkbox. Even the most direct motion by a human has some amount of randomness on the microscopic level: tiny unconscious movements that bots can't easily mimic. If the cursor's movement contains some of this unpredictability, then the test decides that the user is probably legitimate. The reCAPTCHA also may assess the cookies stored by the browser on a user device and the device's history in order to tell if the user is likely to be a bot.
If the test is still unable to determine whether or not the user is a human, it may present an additional challenge, such as the image recognition test described above. However, most of the time the user's cursor movements, cookies, and device history are conclusive enough.
How does reCAPTCHA work without any user interaction?
The latest versions of reCAPTCHA are able to take a holistic look at a user's behavior and history of interacting with content on the Internet. Most of the time, the program can decide based on those factors whether or not the user is a bot, without providing the user with a challenge to complete. If not, then the user will get a typical reCAPTCHA challenge.
Google offers a monthly paid service called reCAPTCHA Enterprise, which uses a score-based detection system to distinguish between humans and bots. reCAPTCHA Enterprise interacts with the customer backend and webpages to trigger a sequence of JavaScript, HTML, and token authentication events. The system then derives the visitor’s risk “score”, from 0.0 through 1.0, and the website developer determines what action should be taken based on the score.
The lower the score, the more likely the “visitor” is actually a bot. A reCAPTCHA Enterprise score of 0.0 indicates that the interaction might be fraudulent and high risk, whereas 1.0 indicates that the interaction is very likely legitimate and low risk.
What triggers a CAPTCHA test?
Some web properties just automatically have CAPTCHAs in place as a proactive defense against bots. Other times, a test may be triggered if user behavior seems to resemble a bot's behavior: if users request webpages or click hyperlinks at a far higher rate than average, for instance.
Are CAPTCHAs and reCAPTCHAs enough for stopping malicious bots?
Some bots can get past the text CAPTCHAs on their own. Researchers have demonstrated ways to write a program that beats the image recognition CAPTCHAs as well. In addition, attackers can use click farms to beat the tests: thousands of low-paid workers solving CAPTCHAs on behalf of bots.
Besides a CAPTCHA, there need to be other strategies in place for stopping unwanted bots (such as content scraping bots, credential stuffing bots, or spam bots).
What are the drawbacks of using CAPTCHAs or reCAPTCHAs to stop bots?
Bad user experience: A CAPTCHA test can interrupt the flow of what users are trying to do, giving them a negative view of their experience on the web property, and leading to them abandoning the webpage altogether in some cases.
Not usable for visually impaired individuals: The problem with CAPTCHAs is that they rely on visual perception. This makes them nearly impossible, not just for people who are legally blind, but for anyone with seriously impaired vision.
These tests can be fooled by bots: As described above, CAPTCHAs are not fully bot-proof and shouldn't be relied upon for bot management.
Are there alternatives to using CAPTCHAs or reCAPTCHAs?
Bot management solutions such as Cloudflare Bot Management or Super Bot Fight Mode can identify bad bots without impacting the user experience, based on the behavior of the bot. This way, bots can be mitigated without forcing users to complete CAPTCHAs.
Cloudflare also offers Turnstile, an invisible alternative to CAPTCHA that uses a snippet of free code. Turnstile is available to anyone — usage does not require being a Cloudflare customer.
How are CAPTCHA and reCAPTCHA related to artificial intelligence (AI) projects?
As millions of users identify hard-to-read text and pick out objects in blurry images, that data is fed into AI computer programs so that they become better at those tasks as well.
In general, computer programs struggle with identifying objects and letters in different contexts, because context can change almost infinitely in the real world. For instance, a stop sign is a red octagon with white letters reading "STOP." A computer program could identify a shape-and-word combination like that fairly easily. However, a stop sign in a photo may look very different from that simple description depending on context: the angle of the photo, the lighting, the weather involved, and so on.
Via machine learning, AI programs can get better at overcoming these limitations. For the stop sign example, the programmer would feed the AI program a bunch of data on what is and is not a stop sign. For this to be effective, they need lots of examples of images with stop signs and images without stop signs, and they need human users to identify them until the program has enough data to be effective at it.
reCAPTCHA helps fill this need by getting humans to identify objects and texts, which slowly provides enough data to build robust AI programs.
What is a Turing test? How are Turing tests relevant to CAPTCHA tests?
A Turing test assesses a computer's ability to mimic human behavior. Alan Turing, an early computing pioneer, invented the concept of a Turing test in 1950. A computer program "passes" the Turing test if its performance during the test is indistinguishable from that of a human – if it acts the way that a human would act. A Turing test is not dependent on getting answers correct; it's about how "human" the answers sound, regardless of whether they're right or wrong.
Although it's called a "Public Turing test," a CAPTCHA is really the opposite of a Turing test – it determines whether a supposedly human user is actually a computer program (a bot) or not, instead of trying to determine if a computer is human. To accomplish this, a CAPTCHA needs to assign a brief task that people tend to be good at and computers struggle with. Identifying text and images usually fits those criteria.