Comment fonctionnent les CAPTCHA | Que signifie CAPTCHA ?
Les CAPTCHA et reCAPTCHA déterminent si un utilisateur est, en réalité, un bot. Ces tests peuvent permettre d'arrêter l’activité de bots malveillants, mais ils sont loin d'être infaillibles.
Objectifs d’apprentissage
Cet article s'articule autour des points suivants :
- Savoir ce qu'est un CAPTCHA et connaître son utilité
- Comprendre la différence entre CAPTCHA et Google reCAPTCHA et les différents types de reCAPTCHA
- Comprendre les avantages et les inconvénients des CAPTCHA pour bloquer les bots malveillants
- Expliquer comment les CAPTCHA sont liés aux projets d'intelligence artificielle (IA)
Contenu associé
Vous souhaitez continuer à enrichir vos connaissances ?
Abonnez-vous à theNET, le récapitulatif mensuel par Cloudflare des informations les plus populaires sur Internet !
Copier le lien de l'article
Qu'est-ce qu'un CAPTCHA ?
Un CAPTCHA est un test conçu pour déterminer si un utilisateur en ligne est vraiment un humain, et non un bot. CAPTCHA est un acronyme qui signifie « Completely Automated Public Turing test to tell Computers and Humans Apart » (c'est-à-dire test de Turing public complètement automatisé pour différencier un humain d'un ordinateur). Les utilisateurs rencontrent souvent des tests CAPTCHA et reCAPTCHA lors de la navigation sur Internet. Même s'ils permettent de gérer l'activité des bots, ces tests présentent des inconvénients.
Bien que les CAPTCHA soient conçus pour bloquer les bots automatisés, ils sont eux-mêmes automatisés. Ils sont programmés pour s'afficher à certains endroits sur un site web et ils approuvent ou refusent automatiquement les utilisateurs.
Comment fonctionne un CAPTCHA ?
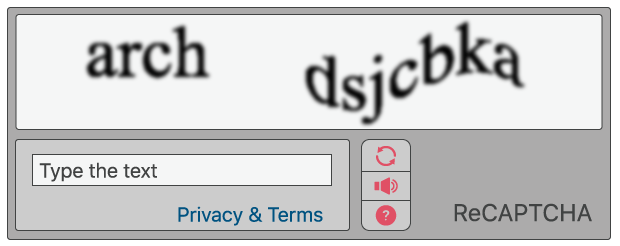
Les CAPTCHA classiques, qui sont encore utilisés aujourd'hui sur certaines propriétés web, consistent à demander aux utilisateurs d'identifier des lettres. Les lettres sont déformées, afin que les bots puissent difficilement les identifier. Pour réussir le test, les utilisateurs doivent interpréter le texte déformé, saisir les lettres correctes dans un champ du formulaire, puis envoyer le formulaire. Si les lettres ne correspondent pas, les utilisateurs sont invités à réessayer. Ces tests sont courants dans les formulaires de connexion, les formulaires de création de compte, les sondages en ligne et les pages de paiement des sites d'e-commerce.

Le principe fondamental est qu'un programme informatique (un bot, par exemple) est incapable d'interpréter les lettres déformées, tandis qu'un être humain, habitué à voir et à interpréter des lettres dans toutes sortes de contextes (différentes polices, écritures, etc.), sera généralement capable de les identifier.
Le mieux que peuvent faire de nombreux bots est de saisir une série de lettres aléatoires, et il est donc statistiquement improbable qu'ils réussissent le test. Ils ne peuvent pas interagir avec le site web ou l'application, tandis que les humains peuvent continuer à les utiliser normalement.
Les bots avancés sont capables d'utiliser l'apprentissage automatique pour reconnaître ces lettres déformées ; c'est pourquoi ces types de tests CAPTCHA sont progressivement remplacés par des tests plus complexes. Google reCAPTCHA a développé un certain nombre d'autres tests permettant de distinguer les utilisateurs humains des bots.
Qu'est-ce que reCAPTCHA ?
reCAPTCHA est un service gratuit de Google, qui remplace les CAPTCHA traditionnels. La technologie reCAPTCHA a été développée par les chercheurs de l'université Carnegie Mellon, puis achetée par Google en 2009.
reCAPTCHA est plus avancé que les tests CAPTCHA classiques. À l'instar de CAPTCHA, certains tests reCAPTCHA exigent que les utilisateurs saisissent du texte contenu dans des images que les ordinateurs parviennent difficilement à déchiffrer. Contrairement aux tests CAPTCHA classiques, reCAPTCHA extrait les textes d'images du monde réel photos d'adresses postales, textes de livres imprimés ou de vieux journaux, et ainsi de suite.
Au fil du temps, Google a étendu les fonctionnalités des tests reCAPTCHA afin qu'ils ne reposent plus uniquement sur l'ancienne méthode consistant à identifier du texte flou ou déformé. Il existe d'autres types de tests reCAPTCHA, parmi lesquels :
- Reconnaissance d'image
- Case à cocher
- Évaluation générale du comportement des utilisateurs (sans aucune interaction avec l'utilisateur)
Comment fonctionne un test reCAPTCHA de reconnaissance d'image ?
Lors d'un test reCAPTCHA de reconnaissance d'images, 9 ou 16 images carrées sont généralement présentées aux utilisateurs. Ces images peuvent toutes provenir d'une même grande image ou être toutes différentes. L'utilisateur doit identifier les images qui contiennent certains objets, tels que des animaux, des arbres ou des panneaux de signalisation. Si sa réponse correspond à celle de la plupart des autres utilisateurs ayant renvoyé le même test, la réponse est considérée comme « correcte », et le test est réussi.

L'identification de certains objets dans des photos floues est une tâche complexe pour un ordinateur. Même les programmes avancés d'intelligence artificielle (IA) s'en acquittent difficilement, et les bots ne font donc guère mieux. Cette tâche ne pose toutefois pas de difficulté particulière à un utilisateur humain, car les humains sont habitués à percevoir des objets quotidiens dans toutes sortes de contextes et de situations.
Comment fonctionnent les tests reCAPTCHA avec une simple case à cocher ?
Certains tests reCAPTCHA invitent simplement l'utilisateur à cocher une case à côté de la déclaration « Je ne suis pas un robot ». Cependant, le test ne réside pas dans le fait de cliquer sur la case à cocher, mais plutôt d'effectuer toutes les actions en amont du clic.
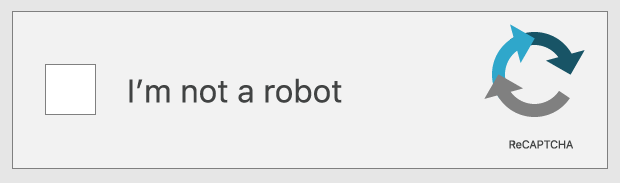
Cette variante du test reCAPTCHA analyse le mouvement du pointeur de l'utilisateur lorsqu'il approche la case à cocher. Même un mouvement extrêmement direct effectué par un être humain comporte une certaine part d'aléatoire, à un niveau microscopique ; il s'agit de minuscules mouvements inconscients que les bots ne peuvent pas facilement imiter. Si le mouvement du curseur comporte une part d'imprévisibilité, le test décide que l'utilisateur est probablement légitime. reCAPTCHA peut également examiner les cookies stockés par le navigateur sur l'appareil d'un utilisateur ainsi que l'historique de l'appareil afin de de déterminer si l'utilisateur est susceptible d'être un bot.
Si le test ne permet toujours pas de déterminer si l'utilisateur est un être humain, il peut présenter à l'utilisateur un défi supplémentaire, comme le test de reconnaissance d'image décrit ci-dessus. Cependant, la plupart du temps, les mouvements du pointeur de l'utilisateur, les cookies et l'historique de l'appareil sont suffisamment concluants.
Comment fonctionnent les tests reCAPTCHA sans interaction avec l'utilisateur ?
Les dernières versions de reCAPTCHA sont capables d'analyser de manière globale le comportement d'un utilisateur et l'historique de ses interactions avec des contenus sur Internet. La plupart du temps, le programme peut, sur la base de ces facteurs, déterminer si l'utilisateur est un bot ou non, sans lui demander de résoudre un test. Si ce n'est pas le cas, une vérification reCAPTCHA classique sera présentée à l'utilisateur.
Google propose un service payant mensuel appelé reCAPTCHA Enterprise, qui utilise un système de détection basé sur un score pour distinguer les humains des bots. reCAPTCHA Enterprise interagit avec le backend du client et les pages web pour déclencher une séquence d'événements JavaScript, HTML et d'authentification par jeton. Le système calcule ensuite le « score » de risque du visiteur, entre 0,0 et 1,0, et le développeur du site web détermine les mesures à prendre en fonction du score.
Moins le score est élevé, plus le « visiteur » est susceptible d'être un bot. Un score reCAPTCHA Enterprise de 0,0 indique que l'interaction pourrait être frauduleuse et comporter un risque élevé, tandis qu'un score de 1,0 indique que l'interaction est très probablement légitime et comporte un risque faible.
Qu'est-ce qui déclenche un test CAPTCHA ?
Certaines propriétés web intègrent automatiquement des CAPTCHA, afin de se protéger proactivement contre les bots. Dans d'autres cas, un test peut être déclenché si le comportement d'un utilisateur est semblable à celui d'un bot ; par exemple, si l'utilisateur consulte des pages web ou clique sur des liens hypertextes à une fréquence considérablement supérieure à la moyenne.
Les CAPTCHA et reCAPTCHA suffisent-ils pour arrêter les bots malveillants ?
Certains robots sont capables de contourner les CAPTCHA textuels, et des chercheurs ont démontré qu'il était également possible d'écrire un programme capable de contourner les CAPTCHA basés sur la reconnaissance d'images. Par ailleurs, les pirates peuvent utiliser des fermes à clics pour réussir les tests : des milliers de travailleurs faiblement rémunérés résolvent les CAPTCHA à la place des bots.
En plus d'un CAPTCHA, d'autres stratégies doivent être mises en place pour bloquer les bots indésirables, tels que les bots d'extraction de contenu, les bots de bourrage d'identifiants (credential stuffing) ou les bots de spam.
Quels sont les inconvénients de l'utilisation de CAPTCHA ou de reCAPTCHA pour arrêter les bots ?
Expérience utilisateur insatisfaisante : un test CAPTCHA peut interrompre le déroulement des actions qu'essaie d'effectuer un utilisateur, suscitant une perception négative de son expérience sur le site web. Il peut même, dans certains cas, l'inciter à délaisser complètement la page web.
Ce système n'est pas utilisable par les personnes malvoyantes : le problème avec les tests CAPTCHA est qu'ils reposent sur la perception visuelle. Cela les rend presque impossibles à utiliser, non seulement pour les personnes aveugles, mais également pour toute personne souffrant d'une déficience visuelle grave.
Ces tests ne sont pas à l'épreuve des bots : comme nous l'avons décrit ci-dessus, les tests CAPTCHA ne sont pas complètement infaillibles face aux bots, et ils ne doivent pas être utilisés aux fins de la la gestion des bots.
Existe-t-il des alternatives à l'utilisation des CAPTCHA ou des reCAPTCHA ?
Les solutions de gestion des bots, telles que Cloudflare Bot Management ou Super Bot Fight Mode, peuvent identifier les bots malveillants sans perturber l'expérience utilisateur, en se basant sur le comportement des bots. Elles permettent ainsi de lutter contre les bots, sans contraindre les utilisateurs à résoudre des CAPTCHA.
Cloudflare propose également Turnstile, une alternative invisible au CAPTCHA, qui utilise un fragment de code gratuit. Turnstile est accessible à tous ; il n'est pas nécessaire d'être client de Cloudflare pour l'utiliser.
Comment les CAPTCHA et reCAPTCHA sont-ils liés aux projets d'intelligence artificielle (IA) ?
Tandis que des millions d'utilisateurs identifient des textes difficiles à lire et sélectionnent des objets dans des images floues, ces données sont fournies à des programmes informatiques d’intelligence artificielle, leur permettant également de s'améliorer dans l'exécution de ces tâches.
En général, les programmes informatiques peinent à identifier les objets et les lettres dans différents contextes, car les changements de contexte dans le monde réel peuvent être quasiment infinis. Par exemple, un panneau stop est un octogone rouge sur lequel le mot « STOP » est écrit en lettres blanches. Un programme informatique pourrait identifier assez facilement une combinaison de formes et de mots. Toutefois, un panneau stop sur une photo peut être très différent de cette simple description, en fonction du contexte : l'angle de la photo, l'éclairage, les conditions météorologiques et bien d'autres paramètres peuvent varier.
Grâce à l'apprentissage automatique, les programmes d'IA peuvent s'affranchir plus facilement de ces limites. Dans l'exemple du panneau stop, le programmeur fournirait au programme d'IA une grande quantité de données décrivant ce qui est et n'est pas un panneau stop. Pour que cette approche soit efficace, le programmeur doit disposer de nombreux exemples d'images avec et sans panneaux stop, et il a besoin d'utilisateurs humains pour les identifier jusqu'à ce que le programme dispose de suffisamment de données pour réaliser efficacement cette opération.
reCAPTCHA répond à ce besoin en demandant à des humains d'identifier des objets et des textes, ce qui fournit progressivement suffisamment de données pour créer des programmes d'IA robustes.
Qu'est-ce qu'un test de Turing ? Pourquoi les tests de Turing sont-ils pertinents pour les tests CAPTCHA ?
Le test de Turing évalue la capacité d'un ordinateur à imiter le comportement humain. Alan Turing, un des pionniers de l'informatique, a inventé le concept du test de Turing en 1950. Un programme informatique « réussit » le test de Turing si ses performances pendant le test sont indiscernables de celles d'un humain, c'est-à-dire s'il se comporte de la même manière qu'un humain. Le test de Turing ne dépend pas de l'exactitude des réponses, mais plutôt de leur caractère « humain », qu'elles soient justes ou fausses.
Bien qu'il soit appelé « test de Turing public », un CAPTCHA est en réalité l'opposé d'un test de Turing : il détermine si un utilisateur supposé humain est en réalité un programme informatique (c'est-à-dire un bot) ou non, au lieu d'essayer de déterminer si un ordinateur est humain. Pour cela, un CAPTCHA doit assigner une brève tâche dont les humains ont tendance à s'acquitter facilement et qui pose des difficultés aux ordinateurs, l'identification de textes et d'images répond habituellement à ces critères.