Come funzionano i CAPTCHA | Cosa significa CAPTCHA?
I CAPTCHA e i reCAPTCHA sono in grado di determinare se un dato utente sia, in realtà, un bot. Sebbene se questi test possono contribuire a bloccare l'attività dei bot dannosi, essi sono tutt'altro che infallibili.
Obiettivi di apprendimento
Dopo aver letto questo articolo sarai in grado di:
- Scopri cosa sono i CAPTCHA, e perché vengono utilizzati
- Impara le differenze tra CAPTCHA e Google reCAPTCHA, e quali sono i diversi tipi di reCAPTCHA
- Comprendi i vantaggi e gli svantaggi dell'utilizzo di CAPTCHA per bloccare i bot dannosi
- Spiega come i CAPTCHA sono legati ai progetti di intelligenza artificiale
Argomenti correlati
Vuoi saperne di più?
Abbonati a theNET, il riepilogo mensile di Cloudflare sulle tematiche più discusse in Internet.
Copia link dell'articolo
Che cosa è un CAPTCHA?
Un test CAPTCHA è progettato per stabilire se un utente online sia realmente un essere umano e non un bot. CAPTCHA è l'acronimo di "Completely Automated Public Turing test to tell Computers and Humans Apart" (test di Turing pubblico e interamente automatico per distinguere esseri computer e esseri umani). Gli utenti si imbattono spesso nei test CAPTCHA e reCAPTCHA su Internet. Questi test rappresentano un modo per gestire l'attività dei bot, anche se questo approccio presenta i suoi svantaggi.
Sebbene i CAPTCHA siano concepiti per bloccare i bot automatizzati, i CAPTCHA sono a loro volta automatizzati. Sono infatti programmati per comparire in determinati punti su un sito web, e approvano o disapprovano automaticamente gli utenti.
Come funziona un CAPTCHA?
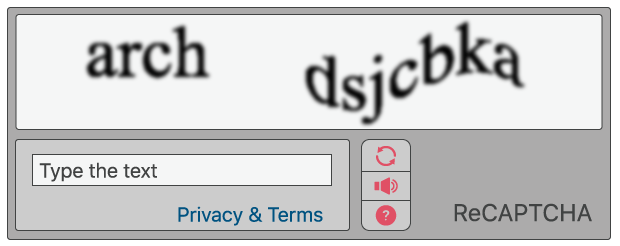
I Captcha classici, che oggi sono ancora utilizzati in alcune proprietà Web, chiedono agli utenti di identificare delle lettere. Le lettere sono distorte in modo tale da rendere estremamente difficile a un bot la loro identificazione. Per superare il test, gli utenti devono interpretare il testo distorto, digitare le lettere corrette nell'apposito campo, e poi premere invio. Se le lettere non corrispondono, gli utenti vengono sollecitati a riprovare. Questo tipo di test è frequente nelle pagine di login, nei moduli di registrazione account, nei sondaggi online e nelle pagine di checkout dei siti di e-commerce.

L'idea alla base è che un programma informatico, come un bot, non sia in grado di interpretare delle lettere distorte, mentre un essere umano, essendo abituato a vedere e interpretare lettere in tutti i tipi di contesti (stili diversi, grafie diverse), sarà di solito in grado di decifrarle.
Il meglio che molti bot sono in grado di fare è inserire delle lettere casuali, rendendo statisticamente improbabile il superamento del test. Pertanto, i bot falliscono la prova e non viene loro concesso di interagire col sito o con l'applicazione, mentre gli utenti umani possono continuare a utilizzarli normalmente.
I bot più avanzati sono in grado di sfruttare l'apprendimento automatico per identificare le lettere distorte, pertanto questo tipo di test CAPTCHA viene progressivamente sostituito da test più complessi. Google reCAPTCHA ha sviluppato un'altra batteria di test con la finalità di distinguere gli utenti umani dai bot.
Che cosa è reCAPTCHA?
reCAPTCHA è un servizio gratuito offerto da Google in sostituzione dei CAPTCHA tradizionali. La tecnologia reCAPTCHA è stata sviluppata dai ricercatori della Carnegie Mellon University, ed è stata successivamente acquisita da Google nel 2009.
reCAPTCHA è più avanzato rispetto agli usuali test CAPTCHA. Come questi ultimi, alcuni reCAPTCHA richiedono che gli utenti inseriscano immagini o testi che i computer decifrano con difficoltà. A differenza dei normali CAPTCHA, i reCAPTCHA estrapolano i testi da immagini tratte dal mondo reale: immagini di indirizzi stradali, brani tratti da libri stampati, testi appartenenti a vecchi giornali e così via.
Nel tempo Google ha ampliato la funzionalità dei test reCAPTCHA, in modo che essi non debbano più fare affidamento sul vecchio metodo di identificazione di righe di testo distorte o sfocate. Gli altri tipi di test reCAPTCHA comprendono:
- Riconoscimento delle immagini
- Casella di spunta
- Valutazione generale del comportamento dell'utente (assenza totale di interazione)
Come funziona un test reCAPTCHA di riconoscimento delle immagini?
In un test CAPTCHA per il riconoscimento dell'immagine, agli utenti di solito vengono presentate 9 o 16 immagini quadrate. Le immagini possono provenire tutte da una singola, grande immagine, oppure possono essere diverse l'una dall'altra. L'utente deve identificare le immagini in cui sono presenti determinati oggetti, come ad esempio animali, alberi o cartelli stradali. Se la sua risposta corrisponde a quella fornita dalla maggior parte degli utenti che hanno completato il medesimo test, la risposta viene considerata "corretta" e l'utente supera il test.

Per i computer, distinguere determinati oggetti da foto sfocate è un problema difficile da risolvere. Anche i programmi avanzati di intelligenza artificiale (IA) hanno difficoltà con questo sistema, pertanto anche un bot ne avrà. Tuttavia, un utente umano dovrebbe riuscire a farlo con una certa facilità, poiché gli esseri umani sono abituati a percepire oggetti di uso quotidiano in tutti i tipi di contesti e situazioni.
Come funzionano i test reCAPTCHA con una singola casella di spunta?
Alcuni test reCAPTCHA si limitano a sollecitare l'utente a barrare una casella di spunta posta accanto alla dichiarazione "non sono un robot". In questo caso, tuttavia, il test vero e proprio non è l'azione dello spuntare la casella, ma tutto ciò che ha portato al "clic" su di essa.
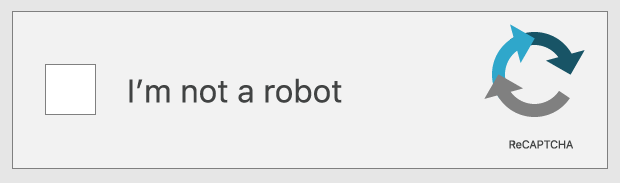
Questo tipo di test reCAPTCHA esamina il movimento del cursore mosso dall'utente mentre si avvicina alla casella di spunta. Qualsiasi movimento umano, per quanto diretto sia, presenta a livello microscopico una certa casualità: minuscoli movimenti inconsci che un bot non è in grado di imitare tanto facilmente. Se il movimento del cursore contiene una certa misura di questa imprevedibilità, il test deciderà che con ogni probabilità l'utente è genuinamente umano. Per determinare se l'utente sia un bot o meno, un reCAPTCHA può inoltre esaminare i cookie memorizzati dal browser sul dispositivo usato dall'utente e la sua cronologia.
Qualora il test non sia ancora in grado di stabilire se l'utente sia umano o meno, potrebbe "alzare il livello" e presentare una sfida addizionale, come il test di riconoscimento dell'immagine descritto sopra. Tuttavia, nella maggior parte dei casi, i movimenti del cursore dell'utente, i cookie e la cronologia del dispositivo sono piuttosto risolutivi.
In che modo reCAPTCHA funziona senza alcuna interazione da parte dell'utente?
Le versioni più recenti di reCAPTCHA sono in grado di approcciarsi in modo olistico al comportamento dell'utente e alla sua storia di interazione con i contenuti presenti su Internet. Il più delle volte, il programma decide se l'utente sia o meno un bot sulla base di questi fattori, senza sottoporre all'utente un test da completare. Se questo non accade, allora l'utente riceverà una tipica "sfida" reCAPTCHA.
Google offre un servizio a pagamento mensile chiamato reCAPTCHA Enterprise, che utilizza un sistema di rilevamento basato su punteggi per distinguere gli esseri umani dai bot. reCAPTCHA Enterprise interagisce con il backend e le pagine Web del cliente per attivare una sequenza di eventi JavaScript, HTML e di autenticazione basata su token. Il sistema calcola quindi il “punteggio” di rischio (o risk score) del visitatore, da 0 a 1, e lo sviluppatore del sito Web determina quale azione intraprendere in base al punteggio.
Più basso è il punteggio, più è probabile che il "visitatore" sia in realtà un bot. Un punteggio reCAPTCHA Enterprise pari a 0 indica che l'interazione potrebbe essere fraudolenta e ad alto rischio, mentre un punteggio pari a 1 indica che è molto probabile che l'interazione sia legittima e a basso rischio.
Che cosa attiva un test CAPTCHA?
Alcune proprietà web implementano automaticamente i CAPTCHA come mezzo di difesa proattivo contro i bot. In altri casi, un test può attivarsi se il comportamento dell'utente assomiglia a quello di un bot: ad esempio, se gli utenti richiedono pagine Web o cliccano sui collegamenti ipertestuali a un tasso molto più elevato rispetto alla media.
I CAPTCHA e i reCAPTCHA sono sufficienti per bloccare i bot dannosi?
Alcuni bot sono in grado di superare i CAPTCHA di testo autonomamente. I ricercatori hanno inoltre dimostrato che è possibile scrivere un programma capace di battere i CAPTCHA a riconoscimento di immagine. Inoltre, gli aggressori possono usare delle "fabbriche di click"per superare i test, in cui migliaia di lavoratori sottopagati che risolvono i CAPTCHA al posto dei bot.
Accanto ai CAPTCHA, è indispensabile mettere in atto altre strategie per fermare i bot indesiderati (come quelli per lo scraping dei contenuti, i bot per il credential stuffing, o i bot spam).
Quali sono gli inconvenienti dell'utilizzo di CAPTCHA o reCAPTCHA per fermare i bot?
Esperienza utente insoddisfacente: un test CAPTCHA può interrompere ciò che il cliente stava cercando di fare in quel momento, dandogli una cattiva impressione della proprietà Web, e in alcuni casi lo può portare ad abbandonare del tutto la pagina che stava visitando.
Non sono utilizzabili per le persone affette da gravi deficit visivi: il problema coi CAPTCHA è che si basano sulla percezione visiva, e ciò ne rende impossibile l'utilizzo non solo da parte di persone legalmente cieche, ma da chiunque abbia la vista gravemente compromessa.
Questi test possono essere ingannati dai bot: come descritto in precedenza, i CAPTCHA non sono completamente "a prova di bot", e pertanto non è possibile fare affidamento esclusivo su di loro per la gestione dei bot.
Esistono alternative all'utilizzo di CAPTCHA o reCAPTCHA?
Le soluzioni per la gestione dei bot, come Cloudflare Bot Management o la modalità Super Bot Fight, sono in grado di identificare i bot dannosi senza impatti sull'esperienza cliente, semplicemente basandosi sul comportamento del bot. In questo modo, è possibile mitigare i bot senza obbligare gli utenti a completare dei test CAPTCHA.
Cloudflare offre anche Turnstile, un'alternativa invisibile al CAPTCHA che utilizza un frammento di codice libero. Turnstile è disponibile per tutti: per utilizzarlo non è necessario essere clienti Cloudflare..
In che modo i CAPTCHA e i reCAPTCHA sono collegati ai progetti di intelligenza artificiale (IA)?
Quando milioni di utenti identificano testi difficili da leggere e identificano oggetti in immagini sfocate, i dati vengono immessi in programmi di intelligenza artificiale, in modo che essi stessi possano migliorare nell'esecuzione di questi compiti.
In genere i programmi informatici incontrano notevoli difficoltà nell'identificare oggetti e lettere nei contesti più svariati. Questo accade perché il contesto, nella vita reale, può mutare quasi all'infinito. Per esempio, un cartello di stop è un ottagono di colore rosso recante la scritta "STOP" in stampatello di colore bianco. Un computer sarebbe in grado di identificare abbastanza facilmente una combinazione forma-testo come questa. Tuttavia, un cartello di stop in una fotografia può apparire, a seconda del contesto, notevolmente diverso da questa semplice descrizione: l'angolazione della foto, l'illuminazione, le condizioni meteorologiche e così via.
Grazie al machine learning, i programmi di intelligenza artificiale possono migliorare nel superare queste limitazioni. Per quanto riguarda l'esempio del segnale di stop, il programmatore dovrebbe fornire al programma di intelligenza artificiale una serie di dati su cosa è e cosa non è un segnale di stop. Affinché ciò sia efficace, avranno bisogno di molti esempi di immagini con segnali di stop e immagini senza segnali di stop, e avranno bisogno che gli utenti umani li identifichino finché il programma non ha dati sufficienti per essere efficace.
I reCAPTCHA contribuiscono a soddisfare questa esigenza facendo in modo che degli umani identifichino immagini e testi. Questo permette di accumulare lentamente abbastanza dati per costruire programmi di intelligenza artificiale solidi e affidabili.
Cosa è un test di Turing? In che modo i test di Turing sono importanti per i test CAPTCHA?
Un test di Turing esamina la capacità di un computer di imitare il comportamento umano. Alan Turing, uno dei primi pionieri dell'informatica, concepì l'idea del test omonimo nel 1950. Un programma informatico "supera" il test di Turing se il suo comportamento nel corso del test risulta indistinguibile da quello di un essere umano: in poche parole, se il computer si comporta come farebbe un umano. Un test di Turing non dipende dalla correttezza delle risposte, ma dal loro grado di "umanità", indipendentemente dal fatto che siano giuste o sbagliate.
Sebbene un CAPTCHA sia chiamato un "test di Turing pubblico", in realtà è l'esatto opposto di un test di Turing. Infatti, il CAPTCHA deve stabilire se un presunto utente umano sia in realtà un programma informatico (un bot) o meno, invece se determinare se un computer sia umano. Per raggiungere questo obiettivo, un CAPTCHA deve assegnare un compito che gli umani sono bravissimi a risolvere, e dove invece i computer incontrano enormi difficoltà. L'identificazione di testi e immagini di solito soddisfa questo criterio.