CAPTCHAの仕組み | CAPTCHAの意味とは?
CAPTCHAとreCAPTCHAはユーザーが実際にはボットであるかどうかを判定します。 これらのテストは悪意のあるボットの活動を止めことに役立ちますが、けして完全な仕組みではありません。
学習目的
この記事を読み終えると、以下のことができるようになります。
- CAPTCHAとは何か、それが使用される理由とは何かを知る
- CAPTCHAとGoogle reCAPTCHAの違い、異なるタイプのreCAPTCHAについて知る
- 悪意のあるボットをブロックするためにCAPTCHAを使用する利点と欠点を理解する
- CAPTCHAと人工知能(AI)プロジェクトとの関連性について説明する
関連コンテンツ
さらに詳しく知りたいとお考えですか?
是非、Cloudflareが毎月お届けする「theNET」を購読して、イン�ターネットで最も人気のある洞察をまとめた情報を入手してください!
記事のリンクをコピーする
CAPTCHAとは?
CAPTCHAテストは、オンラインユーザーが本当に人間であり、ボットではないかどうかを判断するように設計されています。CAPTCHAは「Completely Automated Public Turing test to tell Computers and Humans Apart(完全に自動化された、コンピューターと人間を区別する公開 チューリングテスト )」を表す頭字語です。ユーザーは、インターネット上で頻繁にCAPTCHAおよびreCAPTCHAテストに遭遇します。こうしたテストは、ボット管理活動の一つの方法ですが、このアプローチには欠点もあります。
CAPTCHAは自動化されたボットをブロックするように設計されていますが、CAPTCHA自体が自動化されています。Webサイト上の特定の場所にポップアップするようにプログラムされており、自動的にユーザーを合格または不合格にします。
CAPTCHAの仕組みは?
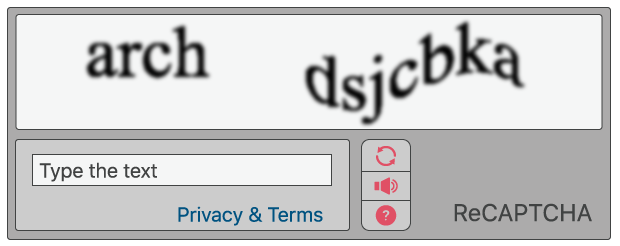
今日でも一部のWebプロパティで使用される従来のCAPTCHAは、文字を識別するようユーザーに指示します。 ボットには文字を識別できないように、表示される文字は曲がっています。 テストに合格するために、ユーザーは歪曲された文字を読み、正しい文字列を入力し、フォームを送信する必要があります。 入力された文字が一致しない場合、ユーザーは再試行します。 こうしたテストは、ログインフォーム、アカウント作成、オンライン投票および電子商取引チェックアウトページなどで一般的に利用されています。

人間はあらゆる種類のコンテキスト(異なるフォント、異なる筆跡など)の文字を見て解釈することに慣れているため、通常、歪曲された文字を解釈することができる一方、ボットのようなコンピュータープログラムにはできない、という考えに基づきます。
多くのボットが取れる最善策は、ランダムに文字を入力することですが、統計的に、テストに合格する可能性はほとんどありません。したがって、ボットはテストに失敗し、Webサイトまたはアプリケーションの操作がブロックされますが、人間は通常のように使用し続けることができます。
高度なボットは、機械学習を使用してこれらの歪んだ文字を識別することができるため、こうしたCAPTCHAテストはより複雑なテストに置き換えられています。Google reCAPTCHAは、人間のユーザーとボットを選別するために、多数のテストを開発しました。
reCAPTCHAとは?
reCAPTCHAは、Googleの提供する無料サービスで、従来のCAPTCHAを置換するものです。reCAPTCHA技術はカーネギーメロン大学の研究者によって開発され、2009年にGoogleが買収しました。
reCAPTCHAは、一般的なCAPTCHAテストよりも高度です。CAPTCHAと同様に、一部のreCAPTCHAでは、ユーザーはコンピューターでは解読困難なテキストの画像を入力する必要があります。通常のCAPTCHAとは異なり、reCAPTCHAは実世界の画像からテキストを取得します。住所の写真、書物の文字、古い新聞の文字などです。
Googleは時間をかけてreCAPTCHAテストの機能性を拡張してきており、不明瞭もしくは歪曲されたテキストを識別する旧来のスタイルに依存する必要がなくなりました。その他のreCAPTCHAテストには以下のようなものがあります。
- 画像認識
- チェックボックス
- 一般ユーザー挙動評価(ユーザーによる操作なし)
画像認識reCAPTCHAテストの仕組みは?
画像認識reCAPTCHAテストの場合、通常、ユーザーには9個または16個の四角形の画像が表示されます。画像は、すべて同一の大きな画像をもとにする場合もあればそれぞれ異なる場合もあります。ユーザーは、動物、木、道路標識などの特定の対象物を含む画像を識別する必要があります。ユーザーの回答が、同じテストに回答した他のユーザーの大多数からの回答と一致する場合、答えは「正解」と見なされ、ユーザーはテストに合格します。

ぼやけた写真から特定の対象物を選択することは、コンピューターには難しい課題です。高度な人工知能(AI)プログラムでさえ苦労します。そのため、ボットも苦労します。ですが、人間は、あらゆる種類のコンテキストや状況で日常的な対象物を認識することに慣れているため、人間のユーザーはかなり簡単にこれを行うことができるはずです。
単一のチェックボックスを使用したreCAPTCHAテストの仕組みは?
reCAPTCHAテストの中には、「私はロボットではありません。」という文言の横にあるボックスをチェックするようユーザーに促すものもあります。しかし、テストはチェックボックスをクリックするという行為ではありません。チェックボックスをクリックするまでのすべてがテストです。
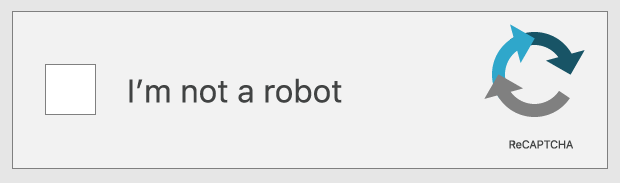
このreCAPTCHAテストでは、チェックボックスに近づくときのユーザーのカーソルの動きが考慮されます。人間の場合、最も直接的な動きでさえ、顕微鏡レベルではある程度のランダム性を持っています。ボットが簡単に模倣できない小さな無意識の動きです。カーソルの動きにこの予測不可能性が含まれている場合、テストはユーザーが正当であると判断します。reCAPTCHAは、ユーザーがボットである可能性が高いかどうかを判断するために、ユーザーデバイスのブラウザに保存されたCookieとデバイスの履歴を評価することもあります。
ユーザーが人間かどうかをテストで判断できない場合、上記の画像認識テストなど、追加の課題が発生する可能性があります。ただし、ほとんどの場合、ユーザーのカーソルの動き、Cookie、およびデバイスの履歴は判断に十分です。
ユーザーの操作なしでreCAPTCHAはどのように機能しますか?
最新版のreCAPTCHAは、ユーザーの挙動とインターネット上のコンテンツの操作履歴を総合的に確認することができます。ほとんどの場合、プログラムはこれらの要因に基づいて、ユーザーに課題を課すことなくユーザーがボットかどうかを判断できます。判断ができない場合、ユーザーには通常のreCAPTCHAの課題が課されます。
GoogleはreCAPTCHA Enterpriseという月額有料サービスを提供しており、スコアベースの検出システムを使って人間とボットとを区別しています。reCAPTCHA Enterpriseは、顧客のバックエンドやウェブページと連動し、JavaScript、HTML、トークン認証といった一連のイベントをトリガーします。そしてシステムが0.0から1.0までのWeb訪問者のリスク「スコア」を導き出し、Webサイト開発者はそのスコアに基づいて取るべき行動を決定します。
点数が低ければ低いほど、「Web訪問者」が実際にはボットである可能性が高くなります。reCAPTCHA Enterpriseのスコアが0.0であれば、そのやり取りは詐欺である可能性がありリスクが高いことを示し、1.0であればそのやり取りは合法である可能性が非常に高く、リスクが低いことを示します。
CAPTCHAテストを起動するのは?
一部のWebプロパティでは、ボットに対する予防的な防御として自動的にCAPTCHAが起動されます。そうでない場合には、ユーザー挙動がボットの振る舞いに似ている時にはテストが開始されます。たとえば、ユーザーが平均よりもはるかに高い割合でWebページをリクエストしたり、ハイパーリンクをクリックしたりする場合などです。
悪意のあるボットを止めるにはCAPTCHAおよびreCAPTCHAだけで十分ですか?
一部のボットは、テキストCAPTCHAに合格することができます。研究者は、画像認識CAPTCHAにも勝てるプログラムを作成する方法も実証しています。さらに、攻撃者はクリックファームを使用して、ボットに代わってCAPTCHAを解決する何千人もの低賃金労働者によってテストに打ち勝つことができます。
CAPTCHAに加えて、望ましくないボット(コンテンツスクレイピングボット、クレデンシャルスタッフィングボット、スパムボットなど)を止めるために、その他の対策が必要なことがあります。
ボットを止めるためにCAPTCHAやreCAPTCHAを使用する欠点とは?
不快なユーザー体験:CAPTCHAテストは、ユーザーがやろうとしていることの流れを妨げ、Webプロパティに関するユーザー体験が否定的になり、場合によってはWebページが完全に放棄される可能性があります。
視覚障害者には利用不可: CAPTCHAの問題は、視覚に依存していることです。これにより、法的に盲目な人だけでなく、重度の視覚障害を持つ人にとっても、利用はほぼ不可能です。
これらのテストはボットに惑わされる可能性があります:上記のように、CAPTCHAは完全にボットを排除できるわけではなく、ボット管理のために依存すべきではありません。
CAPTCHAまたはreCAPTCHAの代わりに使用できるものは?
Cloudflare Bot ManagementやSuper Bot Fight Modeなどのボット管理ソリューションは、ボットの振る舞い基づいて、ユーザーエクスペリエンスに影響を及ぼすことなく悪意のあるボットを識別することができます。こうすることで、ユーザーにCAPTCHAを入力してもらわずに、ボットを軽減することができます。
Cloudflareはまた、フリーコードのスニペットを使用する、CAPTCHAの代替手段として可視性のないTurnstileも提供しています。Turnstileは誰でも利用可能で、Cloudflareの顧客である必要はありません。
CAPTCHAとreCAPTCHAはどのように人工知能(AI)プロジェクトと関係していますか?
何百万ものユーザーが読み取りにくいテキストを識別し、不明瞭な画像から対象物を選ぶと、このデータがAIコンピュータープログラムに供給され、AIによるこうしたタスクの処理も改善されていきます。
一般に、コンピュータープログラムは異なるコンテキストで対象物や文字を識別するのに苦労します。これは、現実世界ではコンテキストの変化に無限の可能性があるためです。たとえば、一時停止標識は赤い八角形に白い文字で「STOP」と表示されたものです。コンピュータープログラムは、そのような形状と単語の組み合わせをかなり簡単に識別できます。ですが、一時停止標識の写真の場合、写真の角度、照明、天候などのコンテキストによって、単純な描写とは大きく異なる場合があります。
機械学習により、AIプログラムはこうした制限を克服することができるようになります。一時停止標識の例では、プログラマーはAIプログラムに一時停止標識とそうでないものに関するデータを入力します。これが有効になるためには、一時停止標識のある画像と一時停止標識のない画像の例が多く必要です。また、プログラム自身が有効になるまでには、十分なデータが得られるまで、人間のユーザーがそれらを識別する必要があります。
reCAPTCHAは、人間に対象物とテキストを識別させることにより、少しずつ、強健なAIプログラムを構築するために十分なデータを提供して、この必要性に貢献します。
チューリングテストとは何ですか?チューリングテストはCAPTCHAテストとどのように関連していますか?
チューリングテストは、人間の挙動を模倣するコンピューターの能力を評価します。チューリングテストの概念は、初期のコンピューターのパイオニア、アラン・チューリングによって1950年に開発されました。チューリングテスト中のコンピュータープログラムのパフォーマンスが人間のパフォーマンスと区別がつかない場合–つまり、人間がするであろう行動をすれば、そのプログラムはテストに「合格」します。チューリングテストは、回答が正解であるかどうかに依存しません。回答が正解かどうかにかかわらず、どれだけ「人間」らしいかが問題なのです。
「公開チューリングテスト」と呼ばれていますが、CAPTCHAは本当はチューリングテストの反対です。CAPTCHAは、人間とされるユーザーが本当はコンピュータープログラム(ボット)かどうかを判断するのであって、コンピューターが人間かどうかを判断するのではありません。これを達成するために、CAPTCHAは、人間が得意とする傾向があり、コンピューターが苦労するような、短いタスクを割り当てる必要があります。テキストや画像の識別は通常この要件に合致します。