What is load balancing?
Load balancing is the practice of distributing computational workloads between two or more computers. On the Internet, load balancing is often employed to divide network traffic among several servers. This reduces the strain on each server and makes the servers more efficient, speeding up performance and reducing latency. Load balancing is essential for most Internet applications to function properly.
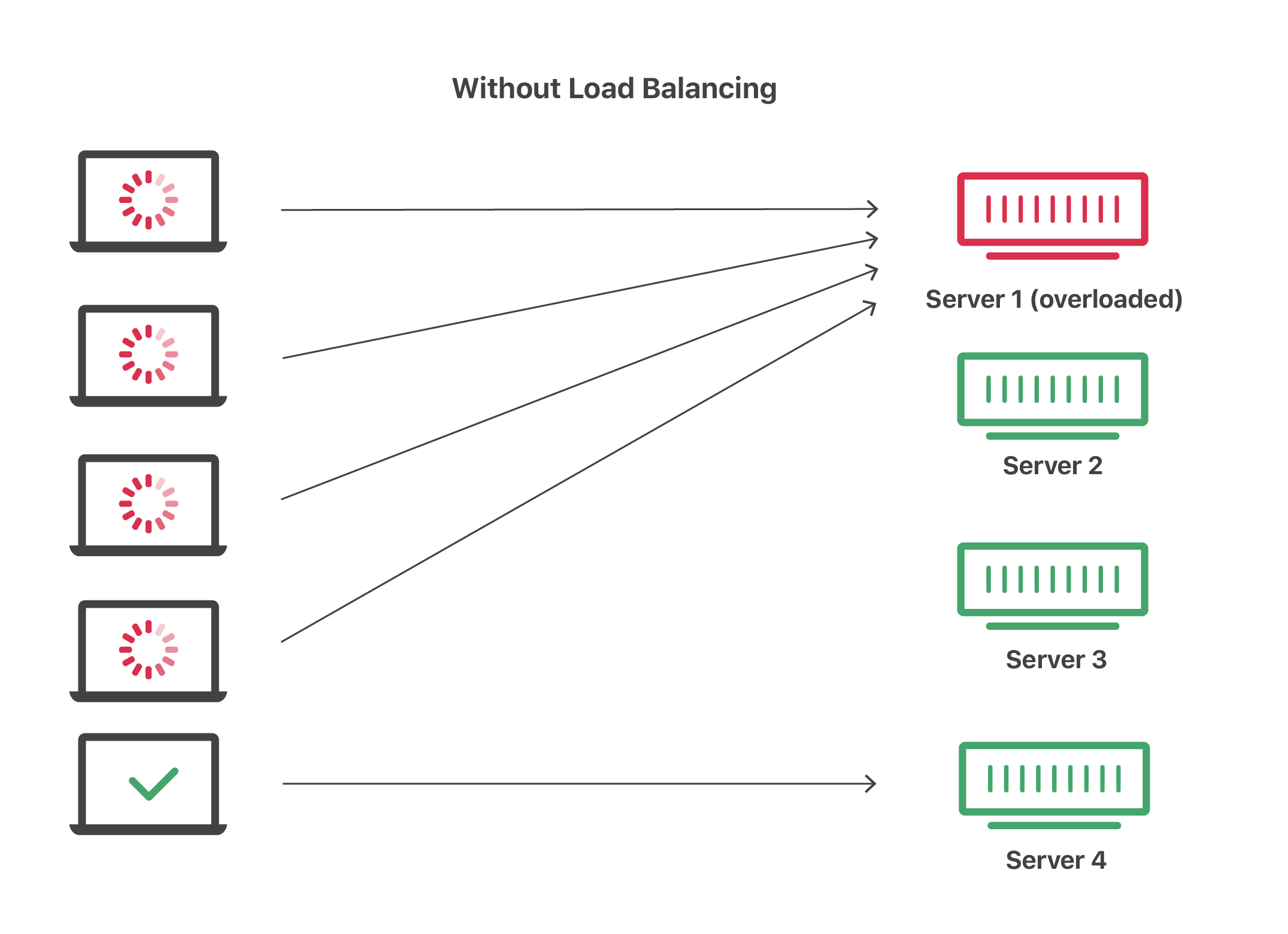
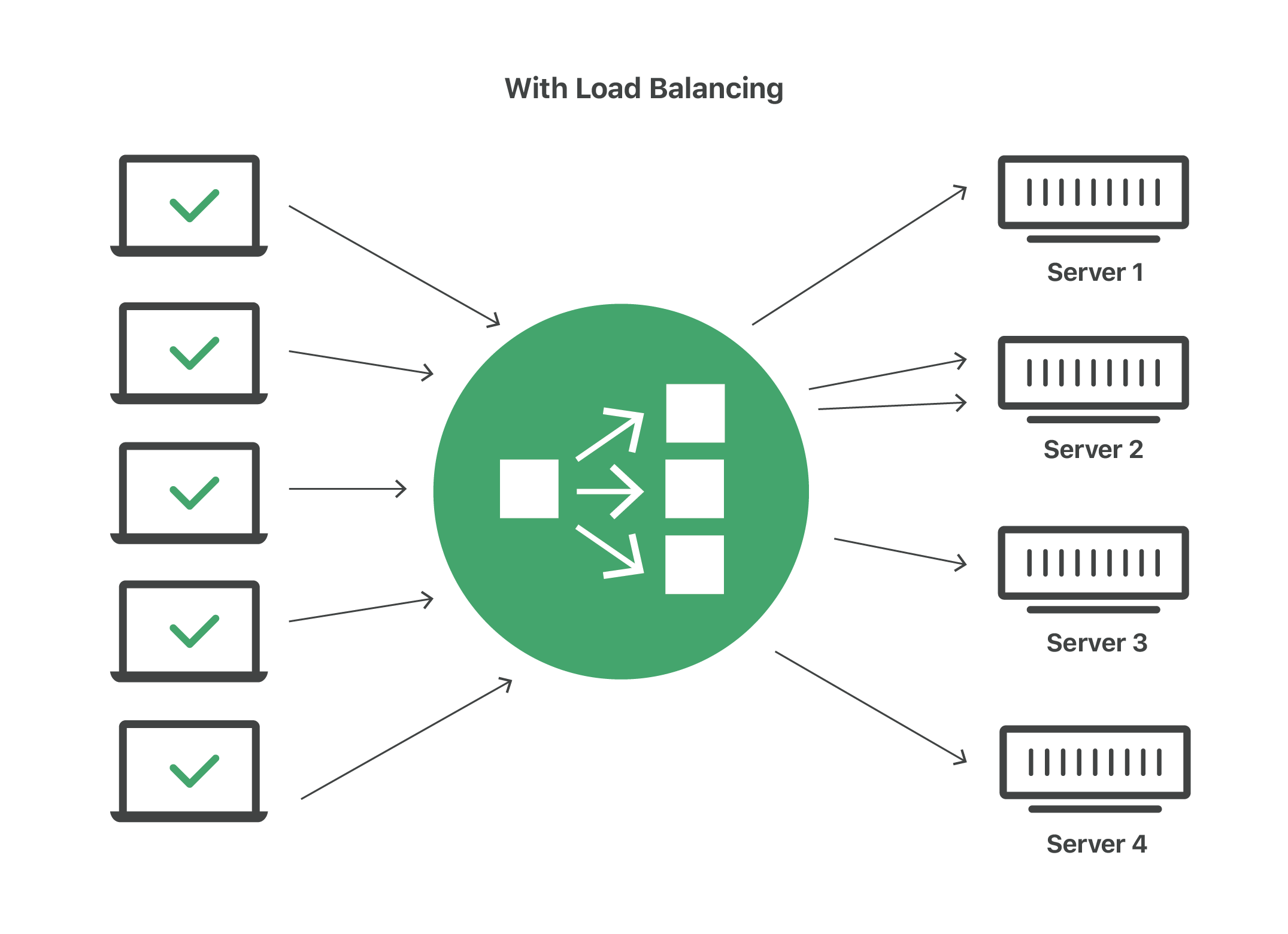
Imagine a checkout line at a grocery store with 8 checkout lines, only one of which is open. All customers must get into the same line, and therefore it takes a long time for a customer to finish paying for their groceries. Now imagine that the store instead opens all 8 checkout lines. In this case, the wait time for customers is about 8 times shorter (depending on factors like how much food each customer is buying).
Load balancing essentially accomplishes the same thing. By dividing user requests among multiple servers, user wait time is vastly cut down. This results in a better user experience — the grocery store customers in the example above would probably look for a more efficient grocery store if they always experienced long wait times.
How does load balancing work?
Load balancing is handled by a tool or application called a load balancer. A load balancer can be either hardware-based or software-based. Hardware load balancers require the installation of a dedicated load balancing device; software-based load balancers can run on a server, on a virtual machine, or in the cloud. Content delivery networks (CDN) often include load balancing features.
When a request arrives from a user, the load balancer assigns the request to a given server, and this process repeats for each request. Load balancers determine which server should handle each request based on a number of different algorithms. These algorithms fall into two main categories: static and dynamic.
Static load balancing algorithms
Static load balancing algorithms distribute workloads without taking into account the current state of the system. A static load balancer will not be aware of which servers are performing slowly and which servers are not being used enough. Instead it assigns workloads based on a predetermined plan. Static load balancing is quick to set up, but can result in inefficiencies.
Referring back to the analogy above, imagine if the grocery store with 8 open checkout lines has an employee whose job it is to direct customers into the lines. Imagine this employee simply goes in order, assigning the first customer to line 1, the second customer to line 2, and so on, without looking back to see how quickly the lines are moving. If the 8 cashiers all perform efficiently, this system will work fine — but if one or more is lagging behind, some lines may become far longer than others, resulting in bad customer experiences. Static load balancing presents the same risk: sometimes, individual servers can still become overburdened.
Round robin DNS and client-side random load balancing are two common forms of static load balancing.
Dynamic load balancing algorithms
Dynamic load balancing algorithms take the current availability, workload, and health of each server into account. They can shift traffic from overburdened or poorly performing servers to underutilized servers, keeping the distribution even and efficient. However, dynamic load balancing is more difficult to configure. A number of different factors play into server availability: the health and overall capacity of each server, the size of the tasks being distributed, and so on.
Suppose the grocery store employee who sorts the customers into checkout lines uses a more dynamic approach: the employee watches the lines carefully, sees which are moving the fastest, observes how many groceries each customer is purchasing, and assigns the customers accordingly. This may ensure a more efficient experience for all customers, but it also puts a greater strain on the line-sorting employee.
There are several types of dynamic load balancing algorithms, including least connection, weighted least connection, resource-based, and geolocation-based load balancing.
Where is load balancing used?
As discussed above, load balancing is often used with web applications. Software-based and cloud-based load balancers help distribute Internet traffic evenly between servers that host the application. Some cloud load balancing products can balance Internet traffic loads across servers that are spread out around the world, a process known as global server load balancing (GSLB).
Load balancing is also commonly used within large localized networks, like those within a data center or a large office complex. Traditionally, this has required the use of hardware appliances such as an application delivery controller (ADC) or a dedicated load balancing device. Software-based load balancers are also used for this purpose.
What is server monitoring?
Dynamic load balancers must be aware of server health: their current status, how well they are performing, etc. Dynamic load balancers monitor servers by performing regular server health checks. If a server or group of servers is performing slowly, the load balancer distributes less traffic to it. If a server or group of servers fails completely, the load balancer reroutes traffic to another group of servers, a process known as "failover."
What is failover?
Failover occurs when a given server is not functioning and a load balancer distributes its normal processes to a secondary server or group of servers. Server failover is crucial for reliability: if there is no backup in place, a server crash could bring down a website or application. It is important that failover takes place quickly to avoid a gap in service.
Learn more about different aspects of load balancing:
Load balancing algorithms Global server load balancing (GSLB)
Load balancing across multiple clouds Cloudflare Load Balancing
FAQs
What is load balancing?
Load balancing is the practice of distributing network traffic or computational workloads across multiple servers to improve an application's performance and reliability.
What is a load balancer?
A load balancer is a tool or application — either hardware-based or software-based — that distributes workloads and traffic among multiple servers.
What is the difference between static and dynamic load balancing algorithms?
Static load balancing algorithms assign traffic based on a predetermined plan, without considering server status, while dynamic algorithms adjust traffic distribution in real time based on server health and performance.
What is server monitoring in load balancing?
Server monitoring involves regularly checking the health and performance of servers so the load balancer can distribute traffic efficiently and avoid overloading unhealthy servers.
What is failover in load balancing?
Failover is the automatic rerouting of traffic to backup servers when a primary server fails, ensuring near-continuous service availability.
How does load balancing improve performance?
Load balancing reduces the strain on each server, making servers more efficient, and helping to make sure all users do not get stuck waiting for responses from the same server (or server pool). This speeds up response times and lowers latency, resulting in faster and more efficient service for users.
What are common load balancing methods?
Common methods include round-robin DNS, weighted round-robin DNS, least connection, weighted least connection, and resource-based load balancing.
Where is load balancing commonly used?
Load balancing is commonly used in web applications, data centers, and large networks to manage and distribute computational workloads effectively.
What is global server load balancing (GSLB)?
Global server load balancing (GSLB) distributes Internet traffic across servers located around the world, helping to optimize performance for users regardless of their location.
How does load balancing affect the user experience?
Load balancing minimizes wait times and ensures a smoother, more responsive service, which leads to a better experience for end users.